Простой пример:
Код:
<?xml version="1.0"?>
<?xml-stylesheet href="chrome://global/skin/" type="text/css"?>
<window xmlns="http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul"
align="center"
title="E4X Text">
<script type="application/x-javascript">
<![CDATA[
function e4x() {
var ns = "http://www.mozilla.org/keymaster/gatekeeper/there.is.only.xul";
var ml = <menulist xmlns={ns} />;
var mp = <menupopup xmlns={ns} />;
var c = 2;
for(var i = 0; i < c; i++)
mp.appendChild(<menuitem xmlns={ns} value={i} label={i} />);
ml.appendChild(mp);
ml.@value = "1";
document.documentElement.appendChild(
new DOMParser().parseFromString(ml.toXMLString(), "application/xml").documentElement
);
}
function dom() {
var ml = document.createElement("menulist");
var mp = document.createElement("menupopup");
var c = 2, mi;
for(var i = 0; i < c; i++) {
mi = document.createElement("menuitem");
mi.setAttribute("value", i);
mi.setAttribute("label", i);
mp.appendChild(mi);
}
ml.appendChild(mp);
ml.setAttribute("value", "1");
document.documentElement.appendChild(ml);
}
]]>
</script>
<button label="E4X" oncommand="e4x();" />
<button label="DOM" oncommand="dom();" />
</window>По идее, обе функции/кнопки должны создавать совершенно одинаковые menulist'ы.
А в результате через document.createElement() создается нормальный список, а через E4X + DOMParser – нечто мелкое, однако внутри и правда список (если прицелиться мышкой, можно его развернуть).
При этом DOM Inspector показывает, что у E4X-menulist'а нету анонимных узлов, отвечающих за «название» и кнопку выпадающего списка: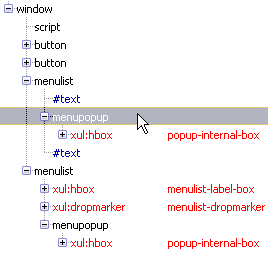
Впрочем, вот тут уже получалось нечто странное после
new DOMParser().parseFromString(xml.toXMLString(), "application/xml").documentElement
Таки хотелось бы окончательно выяснить причину подобных безобразий.
Не знаю на сколько регулярки универсальны, но
Код:
ml = ml. toXMLString (). replace (/[\n\r]/g, "");
ml = ml. replace (/>\s+?</g, "><");
ml = new DOMParser().parseFromString(ml, "application/xml").documentElement;
//ml = document. adoptNode (ml); // для XUL Runner
document. documentElement. appendChild (ml);вместо
Код:
document.documentElement.appendChild(
new DOMParser().parseFromString(ml.toXMLString(), "application/xml").documentElement
);исправляет ситуацию для обоих указанных случаев.
Видимо, плохо стилизуется из-за текстовых узлов.
Видимо, плохо стилизуется из-за текстовых узлов.
Хммм...
Bug 352052 - Add XUL mode to DOMParser
If a XUL document is parsed with DOMParser, it is has to be treated as XML. The
XUL parser in FF parses XUL documents as non-XML. The result is a DOM tree that
is different because DOMParser creates plenty of whitespace text-nodes which
are normally not created by the internal XUL parser.
Это я находил, но не придал особого значения.
11-08-2009 20:10:43
И не радует
Status: UNCONFIRMED
11-08-2009 20:18:58
XML.ignoreWhitespace
true by default. Ignores whitespace between nodes and leading and trailing whitespace in text nodes, which would otherwise be interpreted as text nodes or as part of those text nodes, respectively.
А ведь или я чего-то не понимаю, или не работает.
А вот и решение, по-видимому:
И, вроде бы, все Ok.
https://developer.mozilla.org/en/E4X_Tu … tyPrinting
Тадам?
P.S. А использование регулярок ставит под сомнение фактор быстродействия.
Поигрался.
Кажется, c
XML.prettyPrinting = false;
и правда все правильно отрисовывается, причем начиная с Firefox 1.5.0.12.
Ну, разве что смущает, что XML.prettyPrinting – это глобальное window.XML.prettyPrinting. И если код другого расширения был рассчитан на поведение по умолчанию, получится не очень здорово.
Впрочем,
Код:
var pp = XML.prettyPrinting; XML.prettyPrinting = false; ... xml.toXMLString() ... XML.prettyPrinting = pp;